What We Learned Building a Survival-First Stripe Event Pipeline
Most billing architectures are designed around the happy path.
A customer subscribes.
Stripe creates a subscription.
A webhook arrives.
The application updates its state.
Everyone moves on.
The problem is that production systems rarely live on the happy path.
Networks fail.
Databases become unavailable.
Deployments interrupt workers.
Queues back up.
Events arrive out of order.
Dependencies return errors.
The question is not whether failures occur.
The question is whether the billing system survives them.
That realization fundamentally changed how we approached Stripe integrations in LedgerBill.
Rather than optimizing for ideal conditions, we optimized for survival.
The Wrong Mental Model
Many teams begin with a simple webhook architecture:
Stripe
↓
Webhook Endpoint
↓
Business Logic
↓
Database
At first, this feels efficient.
A webhook arrives and the application immediately updates subscriptions, entitlements, invoices, and customer state.
The problem is that every dependency becomes part of the critical path.
If any component fails, billing state becomes uncertain.
The system is only as reliable as its weakest dependency.
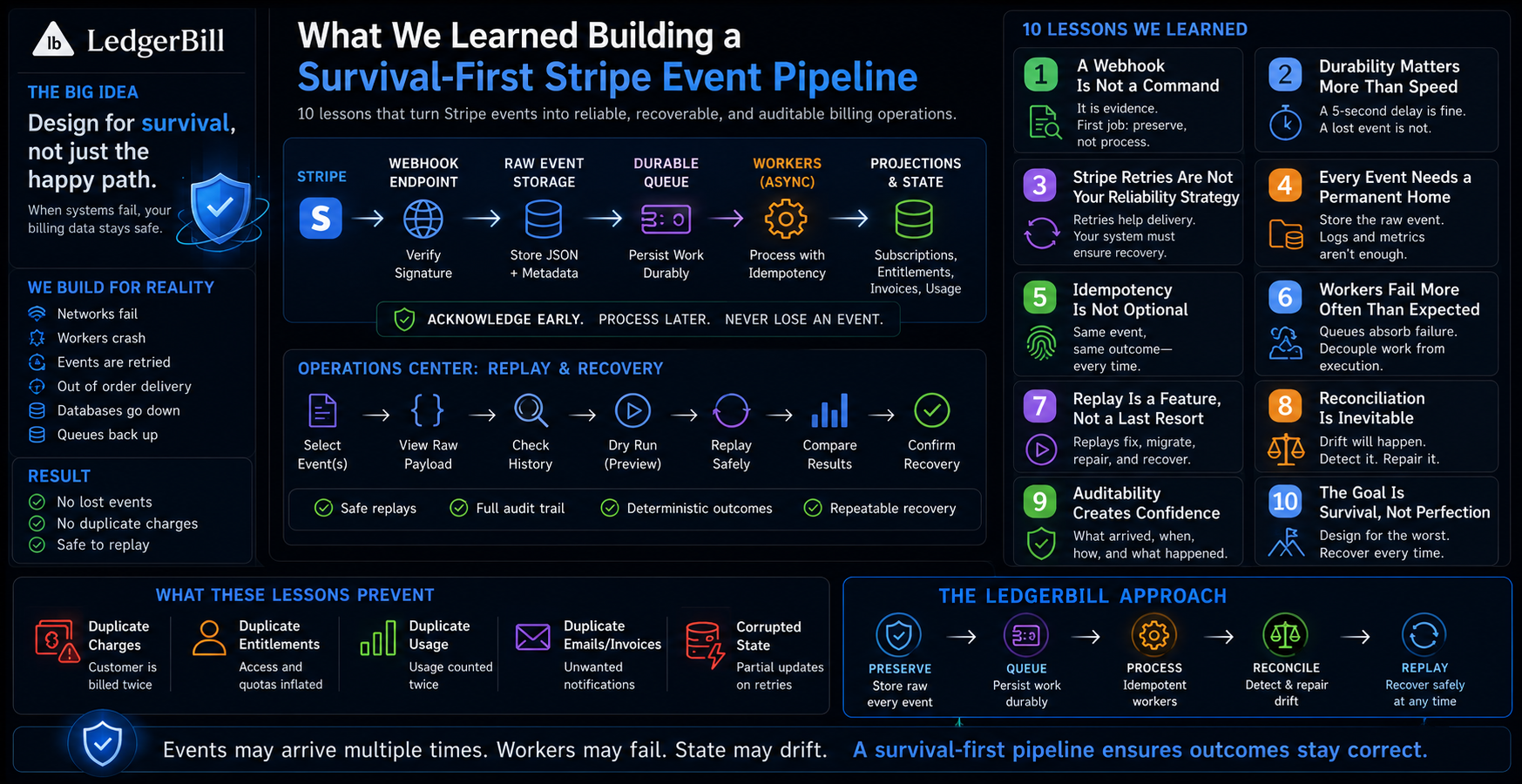
Lesson #1: A Webhook Is Not a Command
One of the most important lessons we learned is that Stripe webhooks should not be treated as commands.
A webhook is evidence.
It tells the platform:
Something happened.
It does not tell the platform:
Execute all business logic immediately.
That distinction matters.
The primary responsibility of a webhook endpoint is not processing.
It is preservation.
Before anything else happens, the event must be captured safely.
Lesson #2: Durability Matters More Than Speed
Many billing systems optimize for immediate processing.
We learned that durability is more valuable.
A webhook that is processed five seconds later is usually acceptable.
A webhook that is lost forever is not.
Our preferred flow became:
Stripe Event
↓
Verify Signature
↓
Store Raw Event
↓
Persist Queue Record
↓
Acknowledge Receipt
↓
Process Later
The objective shifted from:
Process immediately.
to:
Never lose the event.
That single change improved operational resilience dramatically.
Lesson #3: Stripe Retries Are Not a Reliability Strategy
Stripe's retry system is excellent.
It is not a substitute for internal reliability.
Retries answer:
Can Stripe attempt delivery again?
They do not answer:
Can the platform recover safely?
Without durable storage, queueing, and replay capabilities, retries simply delay failure.
A mature billing platform must assume:
- Retries will occur.
- Duplicates will occur.
- Processing failures will occur.
The architecture must be designed accordingly.
Lesson #4: Every Event Needs a Permanent Home
Logs are not enough.
Metrics are not enough.
A billing platform should preserve the original source event exactly as it was received.
Conceptually:
raw_source_events
becomes one of the most valuable datasets in the system.
It provides:
- Audit evidence
- Replay capability
- Incident investigation support
- Historical verification
Months later, the platform can still answer:
What exactly did Stripe send?
That answer is often critical during support escalations and financial reviews.
Lesson #5: Idempotency Is Not Optional
Once durable storage and retries exist, duplicate processing becomes inevitable.
A single Stripe event may arrive multiple times because of:
- Network failures
- Retry behavior
- Queue reprocessing
- Operational replay
Without idempotency, recovery becomes dangerous.
A safe billing pipeline requires:
Event ID
↓
Deduplication
↓
Processing
Every operation must tolerate receiving the same event more than once.
The goal is simple:
Same input, same outcome.
No matter how many times processing occurs.
Lesson #6: Workers Fail More Often Than Expected
Developers often focus on webhook reliability.
In practice, workers become the larger operational challenge.
Workers:
- Restart
- Crash
- Time out
- Lose database connections
- Encounter deployment interruptions
A survival-first architecture assumes these failures are normal.
Queues absorb the impact.
Events remain durable.
Processing resumes later.
The system survives because work and storage are decoupled.
Lesson #7: Replay Is a Feature, Not a Last Resort
Many teams treat replay as an emergency capability.
We learned to treat replay as a normal operational function.
Examples include:
- Projection repair
- Schema migrations
- Billing logic improvements
- Reconciliation recovery
- Historical correction
Replay should be expected.
That means events must remain:
- Durable
- Traceable
- Auditable
- Reproducible
The easier replay becomes, the easier operations become.
Lesson #8: Reconciliation Is Inevitable
Distributed systems drift.
This is not a bug.
It is a property of asynchronous architectures.
Eventually:
Stripe State
≠
Internal Projection
The objective is not eliminating all drift.
The objective is identifying and repairing it safely.
A survival-first pipeline creates the evidence necessary for reconciliation:
- Original event
- Processing history
- Projection history
- Audit records
Without those records, reconciliation becomes guesswork.
Lesson #9: Auditability Creates Confidence
Billing systems serve multiple audiences.
Customers want confidence.
Support wants explanations.
Finance wants evidence.
Engineering wants reproducibility.
Auditability satisfies all four.
Every event should leave behind a trail that explains:
- What arrived
- When it arrived
- How it was processed
- Which systems were affected
- Which outcomes were produced
The billing platform becomes explainable rather than opaque.
Lesson #10: The Goal Is Survival, Not Perfection
Perfect systems do not exist.
Outages happen.
Dependencies fail.
Queues back up.
Workers crash.
Stripe retries.
The objective is not preventing every failure.
The objective is ensuring that failures do not become data loss.
A survival-first architecture asks:
If everything goes wrong right now, can we recover?
If the answer is yes, the platform is resilient.
The LedgerBill Approach
LedgerBill's Stripe event pipeline is built around a simple hierarchy of priorities:
First: Preserve
Store the original event.
Second: Queue
Persist work durably.
Third: Process
Execute business logic asynchronously.
Fourth: Reconcile
Detect and repair drift.
Fifth: Replay
Recover safely when necessary.
This ordering is intentional.
Processing is important.
Survival is more important.
Final Thoughts
Stripe events are the foundation of modern SaaS billing.
But billing reliability is not determined by Stripe alone.
It is determined by how the receiving platform behaves when things go wrong.
A survival-first pipeline assumes:
- Events may arrive multiple times.
- Workers may fail.
- State may drift.
- Replays will be required.
- Recovery is part of normal operations.
When those assumptions become design principles, billing systems become easier to trust, easier to operate, and dramatically more resilient.
Because the most important question in billing is not:
Did the event arrive?
It is:
Can the platform still explain and recover from it six months later?