5 Production Incidents That Billing Teams Can Prevent with Idempotent Design
Most billing incidents do not begin with incorrect pricing.
They begin with systems behaving exactly as distributed systems are designed to behave.
Events arrive twice.
Requests are retried.
Workers restart.
Messages are redelivered.
Operators replay historical events.
None of these situations are unusual.
What determines whether they become incidents is how the billing platform responds.
This is where idempotency matters.
Idempotency ensures that processing the same operation multiple times produces the same outcome.
In billing systems, that capability is not a convenience.
It is a survival requirement.
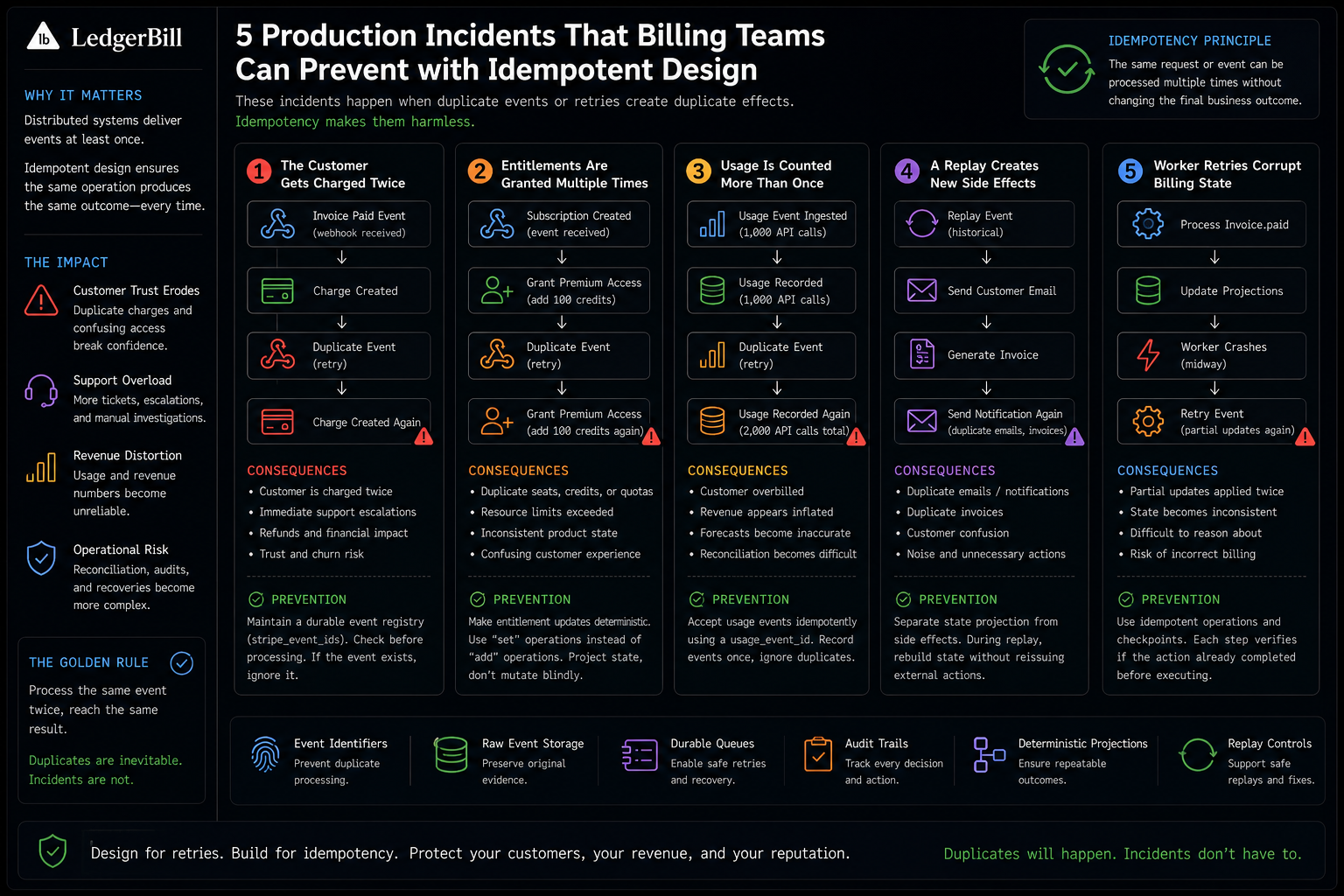
Here are five common production incidents that become dramatically less likely when billing systems are designed around idempotent principles.
Incident #1: The Customer Gets Charged Twice
This is the incident every billing team fears.
A webhook arrives.
Processing succeeds.
The acknowledgement is lost.
The sender retries.
The platform processes the same event again.
Without idempotent handling:
Invoice Paid Event
↓
Charge Created
↓
Duplicate Event
↓
Charge Created Again
The customer is charged twice.
Support tickets arrive immediately.
Finance becomes involved.
Trust erodes.
Prevention
Maintain a durable event registry:
stripe_event_ids
Before processing:
Has this event already been processed?
If yes, ignore it.
The duplicate delivery becomes harmless.
Incident #2: Entitlements Are Granted Multiple Times
Billing systems often trigger entitlement updates.
For example:
Subscription Created
↓
Grant Premium Access
If the same event is processed repeatedly:
Premium Access
Premium Access
Premium Access
unexpected side effects may occur.
Examples include:
- Duplicate resource allocation
- Duplicate seat creation
- Duplicate credits
- Duplicate quotas
The billing state may remain correct while the product state becomes inconsistent.
Prevention
Entitlement operations should be deterministic.
Instead of:
Add 100 Credits
prefer:
Set Credits = 100
State projection is naturally safer than incremental mutation.
Incident #3: Usage Is Counted More Than Once
Usage-based billing introduces additional complexity.
Imagine a metering event:
{
"meter": "api_requests",
"quantity": 1000
}
A retry occurs.
The event is processed twice.
The invoice now reflects:
2,000 Requests
instead of:
1,000 Requests
The customer sees unexpected charges.
Revenue appears inflated.
Reconciliation becomes difficult.
Prevention
Usage ingestion should support event identifiers.
For example:
usage_event_id
A usage event should be accepted once and ignored thereafter.
The platform records consumption once regardless of delivery behavior.
Incident #4: A Replay Creates New Side Effects
Eventually every billing platform needs replay capabilities.
Examples include:
- Projection repair
- Incident recovery
- Historical migration
- Bug remediation
A replay is intended to reconstruct state.
Without idempotent design, replay may accidentally create new business actions.
For example:
Replay Event
↓
Send Customer Email Again
↓
Generate Duplicate Invoice
↓
Trigger Duplicate Notification
What should have been recovery becomes another incident.
Prevention
Separate:
State Projection
from:
External Side Effects
Replay should rebuild internal state without reissuing customer-facing actions unless explicitly requested.
Incident #5: Worker Retries Corrupt Billing State
Consider a worker processing:
invoice.paid
The worker updates several systems:
Invoice Projection
Entitlements
Audit Trail
Notifications
Halfway through processing, the worker crashes.
The queue retries the event.
Without idempotency, some updates occur twice while others occur once.
The resulting state becomes difficult to reason about.
Prevention
Use idempotent operations and processing checkpoints.
Each stage should answer:
Has this action already been completed?
before execution.
This allows retries without introducing corruption.
Why These Incidents Keep Happening
The root cause is rarely a bug.
The root cause is usually an incorrect assumption.
Teams assume:
Events arrive once.
In reality:
Events arrive at least once.
Teams assume:
Workers never fail.
In reality:
Workers fail regularly.
Teams assume:
Retries are rare.
In reality:
Retries are part of normal operation.
Billing architectures must be designed around these realities.
The Building Blocks of Idempotent Billing
Production-grade billing systems typically combine several mechanisms:
Event Identifiers
Prevent duplicate processing.
Raw Event Storage
Preserve source evidence.
Durable Queues
Enable safe retries.
Audit Trails
Track processing history.
Deterministic Projections
Produce repeatable outcomes.
Replay Controls
Support safe recovery.
Together these capabilities transform retries from a risk into a feature.
The LedgerBill Perspective
LedgerBill treats idempotency as foundational infrastructure rather than a narrow implementation detail.
The platform assumes:
- Events may arrive multiple times.
- Workers may restart.
- Replays will occur.
- Recoveries will be necessary.
Event IDs, raw event storage, durable processing pipelines, reconciliation workflows, and audit trails work together to ensure that operational recovery does not change billing outcomes.
The objective is simple:
Process the same event twice and reach the same result.
Final Thoughts
The most expensive billing incidents rarely originate from incorrect formulas.
They originate from duplicate actions.
Duplicate charges.
Duplicate entitlements.
Duplicate usage.
Duplicate notifications.
Duplicate invoices.
Idempotent design prevents these failures by ensuring that repeated execution produces the same business outcome.
Because in distributed systems, duplicates are inevitable.
Production incidents are not.